Screenshot AI (SCAi)
Overview
Screenshot AI (SCAi) is a project that seeks to build neural networks to play complex games based solely off the pixel values of the screen.
Concepts Used:
- Image Recognition
- CNNs
- Autoencoder
- Reinforcement Learning
- Stable Baselines 3
- PPO algorithm
- Stable Baselines 3
How SCAi Works
Right now I am working with the game Overwatch 2, once the model is functional to a satisfactory degree the plan is to extend to other games. The core of the program is using reinforcement learning to train the model. Below is a diagram outlining the process of training the model.
General Info About Game
This is what the game looks like.
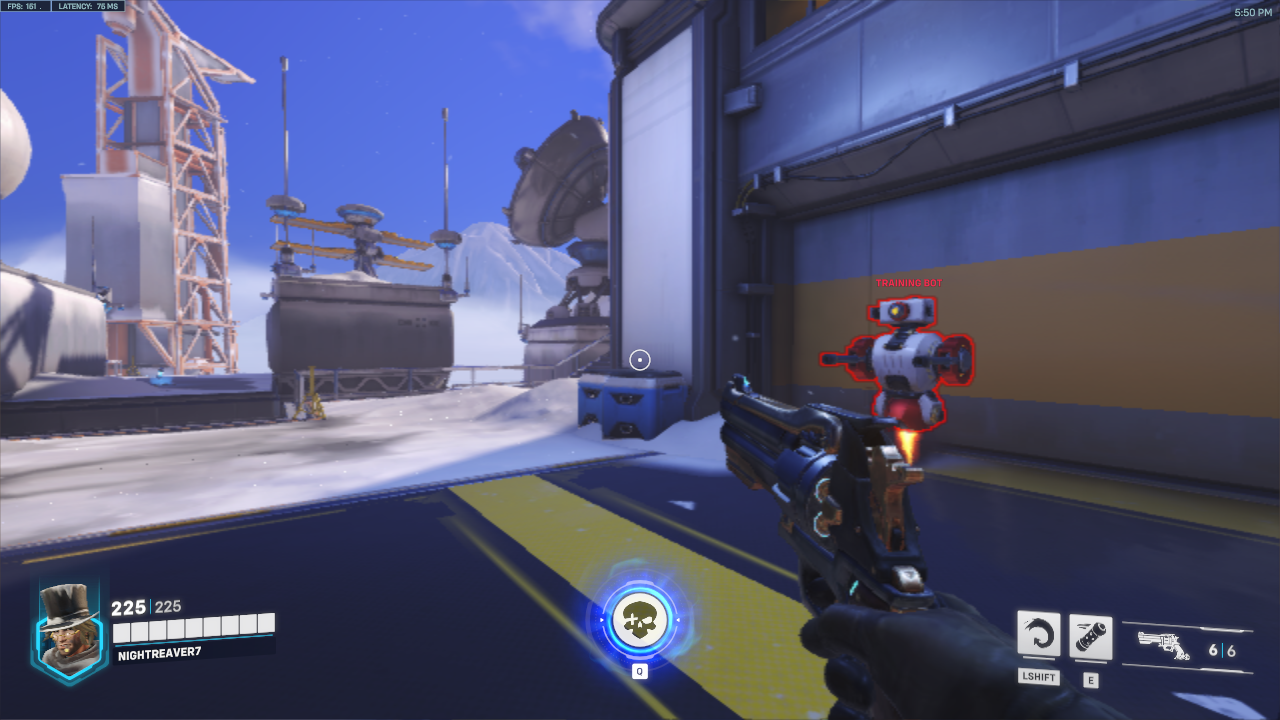
The health is shown in the bottom left corner.
The crosshair is in the center of the screen.
Overwatch 2 is a First Person Shooter game, basically the goal is to shoot other people before they shoot you. It’s a little bit more complicated than that because there are different types of characters, and different gamemodes like capture the point, or escorting a truck through an area, but those will be worked on after the model is good at combat.
Sensing Damage
SCAi senses damage using a neural network. In Overwatch 2, you have two immediate cues to know when you have done damage. One is an audio cue which is harder to sense using a computer. The second cue is a symbol surrounding your crosshair in the middle of the screen. Depending on what type of shot you hit, the symbol will change. There are 3 main symbols,
the kill symbol,

the headshot symbol,

and the bodyshot symbol.

If there is no symbol around the crosshair, then that means you missed.

They symbols can also be mixed together, so if you get a kill when you headshot someone, then it combines the two symbols, and same for a bodyshot + kill. The image below is a body shot + kill.

Sensing Health
SCAi senses damage using another neural network. Health is always displayed in the bottom left corner of the screen. The neural network looks at one number at a time to classify them, and I run the neural network on each of the spots where health numbers could occur. It then concatenates the numbers together to get the actual health.
The health image that is captured looks like this.

It is split up into 3 sections, then each of those sections are processed independently.
What’s Next?
Right now the model is ready to run, the only problem is that my computer is not strong enough to handle the model. The model has an input shape of (720,1280,3) which is way too many inputs for my computer to handle. This is where the image encoder comes in. If the image encoder can compress the information in the image efficiently, then the input size will be much easier to handle.
Image Encoder
My attempts at using an autoencoder to encode the image just ended in low pixel versions of the image, which I could fall back on if nothing else works, but I would prefer to get an encoding that can be decoded to a higher resolution.
The next thing I tried was extracting important features from the image before putting the images through the autoencoder. In Overwatch 2, all enemies have a red outline, so if we filter for a certain range of red then we can filter out everything except for the enemies outlines. This in principle should make it easier for the autoencoder to encode the images because there is less “noise” in the image.
The problem with that approach is that because so much of the image is just black, the decoder decodes the encoded representation of the image to a fully black image every time. Because there is so much black in the input image, and only thin outlines of red, it can get the loss very low by decoding to a fully black image every time.
The next thing I am going to try is randomizing the background color of the input image. I think it might be easier for the model if the background color is randomized, because then the autoencoder can’t predict the background color and will focus on predicting the outlines which would be the only non-randomized part of the image.
If that doesn’t work I will try to change the loss function so it only takes into account the pixels that are not empty in the original image.
GitHub Links
- Damage Sensor Model (97.38% accuracy)
- Health Sensor Model (99.16% accuracy)